
티스토리 뷰
# Image Datastore
머신러닝을 하기 위해서는 수많은 데이터를 사용해 학습시켜야 한다.
이런 이미지들을 모두 불러와서서 학습시키기에는 프로그램에 너무 많은 부담이 된다.
따라서 매트랩에는 이미지를 전부 불러올 필요 없이(변수로 저장해둘 필요 없이),
DataStore가 이미지의 메타데이터를 담아두고 있다가, 필요할 때 직접 꺼내쓰는 방식을 사용한다
=> 메모리 절약, 속도 향상
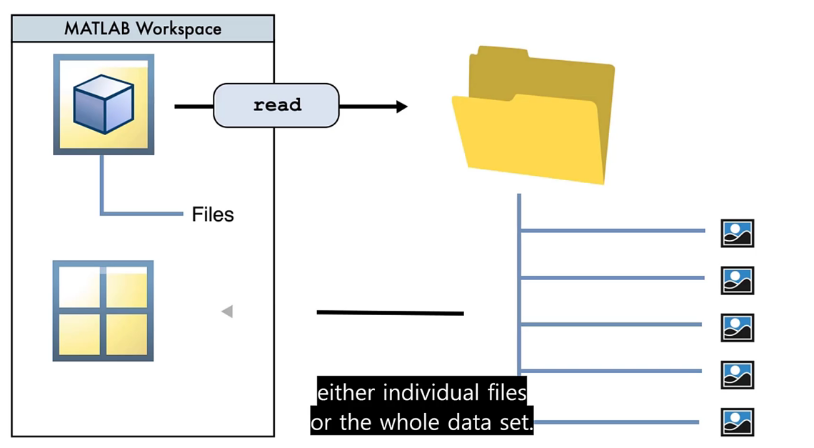
내가 이해한게 맞나 모르겠다.
다른 한글 자료가 없더라. 영어가 필수야 필수;;

다음으로, 이미지의 상태가 정상이 아닌 경우(잘렸거나, 회전했거나, 찌그러졌거나 등..) 전처리 과정을 거칠 필요가 있다.
(Preprocessing)
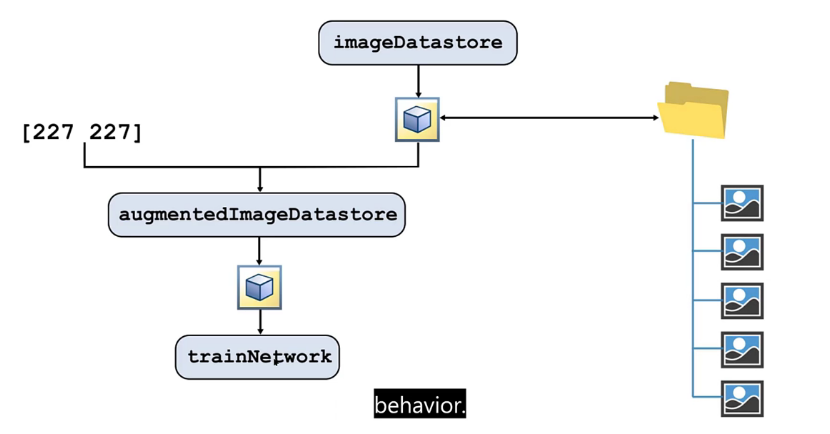
전처리 과정은 "augmentedImageDatastore" 이 담당해서 해준다.
지금까지 한 내용을 정리하면
1. ImageDatastore은 디렉토리 내의 이미지 파일들의 메타데이터 정보를 담고있다.
2. augmentedImageDatastore을 이용해 이미지 리사이즈(227x227) 등 전처리 과정을 거친다
3. 전처리된 이미지를 가지고 모델을 학습시킨다.
(전처리 옵션(?)으로 imageDataAugmenter을 줄 수 있다)

* 매트랩 코드
% ImageDatastore
imageDS = imageDatastore("폴더경로", "IncludeSubfolders", true, "LabelSource", "foldernames")
% 화면에 출력
montage(imageDS)
% 이미지 전처리
augImageDS = augmentedImageDatastore([227 227], imageDS);# Pre-trained된 모델 수정하기 | fully-connected와 output 레이어

pre-trained된 모델을 수정해서 내가 원하는 output 클래스를 예측할 수 있도록 만들어보자.
앞쪽에 feature 추출하는 부분은 손대지 않고 뒤쪽에 fully-connected 레이어와 output 레이어만 손봐주면 된다.
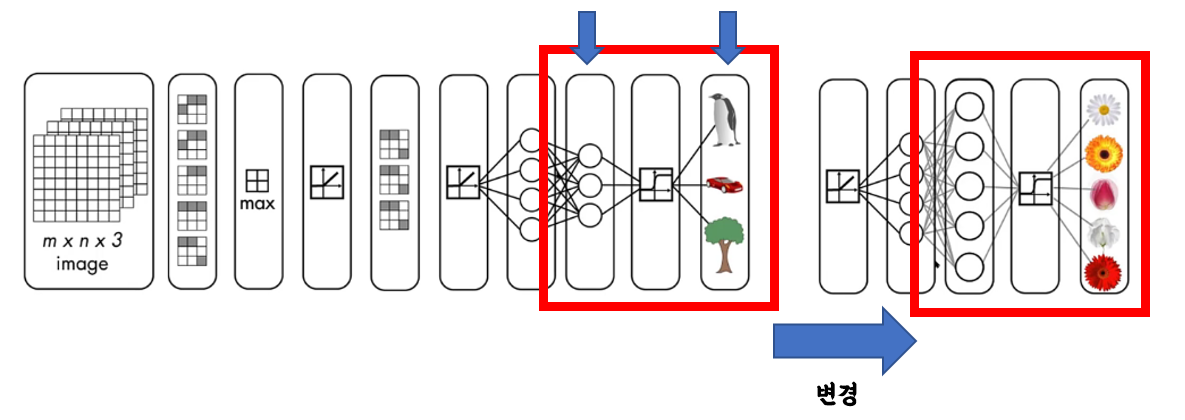
순서상 23번 레이어와 마지막 레이어만 바꿔주면 된다.
어려울 것 같은데 두줄로 끝난다.
layers(23) = fullyConnectedLayer(output클래스 사이즈);
layers(end) = classificationLayer();

보통 모델을 훈련할 때는 Train 셋과 Test 셋을 나눠서 사용해야 한다
Train 셋으로 훈련을 시키고 Test 셋으로 모델을 평가한다.
imageDS = imageDatastore("폴더경로", "IncludeSubfolders", true, "LabelSource", "foldernames");
% Test셋과 Train셋 나누기 (Train이 80%)
[trainImage, testImage] = splitEachLabel(imageDS, 0.8);
% 전처리 과정 거쳐서 데이터 나누기
trainData = augmentedImageDatastore([227 227], trainImage);
testData = augmentedImageDatastore([227 227], testImage);
이후에 모델을 훈련시킨다
opts = trainingOptions("sgdm", "InitialLearnRate", 0.0001, ...
"Plots", "training-progress", "MiniBatchSize", 64);
newnet = trainNetwork(trainData, layers, opts)
* 매트랩 겁~~~~~~~~~~~~~나 무겁다
GPU 그래픽 메모리가 부족하다고 네트워크 훈련이 안된다.
아무래도 큰일난 것 같다.
내 인공지능 공부는 아마 여기까지인 것 같다

해결방법이 없을까?
1. 옵션에서 MiniBatchSize 크기를 줄여라 (기본값=128)
opts = trainingOptions("sgdm", "InitialLearnRate", 0.01, "Plots", "training-progress", "MiniBatchSize", 64);
**** MiniBatchSize는 학습 성능에 큰 영향을 끼치기 때문에 가급적 손대지 않는 것이 좋다
* InitialLearnRate는 경사하강법에서 스텝의 크기를 조절한다. (작을수록 가중치를 조금씩 수정한다, 정확도 향상)
- 솔직히 별 기대는 안하는게 좋다. 어짜피 안될거기 때문
2. GPU 대신 CPU..
opts = trainingOptions("sgdm", "Plots", "training-progress", "ExecutionEnvironment", "cpu");CPU를 대신 혹사시켜서 훈련시키는 방법을 사용해 보았다.
대신 매우 느리다는 점 감안해야한다.. 모델 하나 학습하는데 30분은 걸리는듯
떵컴이라 서럽다 서러워
* 시간이 너무 오래걸리는 것 같으면 옵션에서 "MaxEpochs" 횟수를 줄여서 반복학습 횟수를 줄일 수도 있다
- 네트워크 성능은 조금 떨어질 수도
*** MaxEpoch를 무작정 늘린다고 모델의 성능이 더 좋아지는 것이 아니다 ***
- 오히려 과적합 문제로 Loss율이 증가하는 모습을 보인다.
opts = trainingOptions("sgdm", "InitialLearnRate", 0.01, "MiniBatchSize", 64, "MaxEpochs", 15);

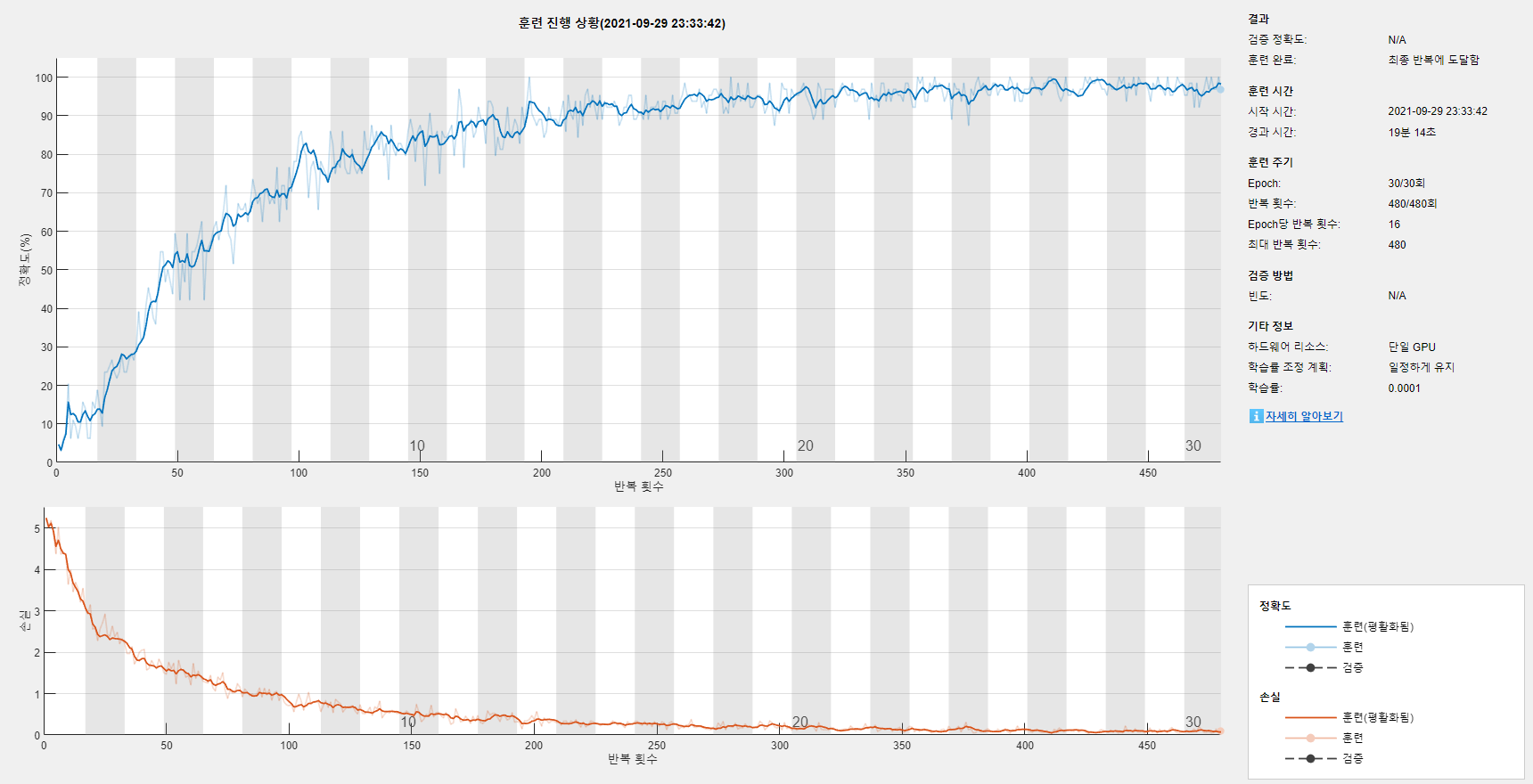
* Mini-batch: 전체 데이터의 서브셋. 서브셋을 학습시킨 이후에 가중치를 수정한다.
* Epoch: 전체 데이터를 n번 학습시킨다
# Training 이후 평가
Training을 했으면 성능이 얼마나 나오는지 평가 해주는게 인지상정.
testPred = classify(newnet, testData); % 모델로 예측한 값
testGT = testImage.Labels; % 실제 값* testGT는 실제 값.
아까 위에서 저장해둔 Imagedatastore 메타데이터를 이용해서 가져온다.
% Case 1.
sum(testPred == testGT)/numel(testPred)
% Case 2.
testAcc = nnz(testPred == testGT)/numel(testPred)<모델의 정확도 계산>
confusionchart(testGT, testPred)<ConfustionChart를 이용해서 한눈에 보기 쉽게>
'학교공부 > 인공지능' 카테고리의 다른 글
| 매트랩으로 배우는 인공지능 - 6 | CNN 레이어 상세 (0) | 2021.10.06 |
|---|---|
| 매트랩으로 배우는 인공지능 - 5 | Training from scratch (0) | 2021.09.30 |
| 매트랩으로 배우는 인공지능 - 4 | Convolution, ReLU, Pooling (0) | 2021.09.30 |
| 매트랩으로 배우는 인공지능 - 2 | 전이학습, CNN (0) | 2021.09.28 |
| 매트랩으로 배우는 인공지능 - 1 | 인공지능, 머신러닝, 딥러닝 (1) | 2021.09.27 |