
티스토리 뷰
CNN에서 Network Training을 할 때 사용되는 option에 대해 알아보자
일단 대략적인 순서는 다음과 같다
1. 학습 데이터를 Train Set, Test Set, Validation Set 세 가지로 나눈다
Training Data - 가중치 학습에 사용되는 데이터
Validation Data - "학습 중" 성능 평가에 사용되는 데이터
Test Data - "학습 모두 끝난 후" 성능 평가에 사용되는 데이터
[trainData, valData, testData] = splitEachLabel(DataSet, 0.8, 0.1, 0.1);
2. option 설정
2-1) 알고리즘
* 대부분의 알고리즘은 "★경사 하강법★"을 기반으로 한다
- Loss Function에서 제일 최소점을 향해 내려가는 것을 목표로 한다.
- 기울기가 낮아지는 쪽으로만 계속 이동하다 보면 언젠가는 최소점에 도달하게 되는 원리를 이용.
- Learning Rate(=Step Size)에 따라 수렴할 수도, 발산할 수도 있다.
+) 경사 하강법은 일반적으로 편미분 수식을 이용한다.
+) 최소점인줄 알았던 점이 최소점이 최소점이 아닐 수 있다 (극소점 != 최소점)
- Convex 함수(아래로 볼록한 함수)만이 극소점이 최소점임을 보장해줄 수 있다

sgdm(Stochastic Gradient Descent with Momentum)
- 경사 하강법인데 거기에 Momentum을 곁들인.
- Momentum - 관성. => 이동 방향을 스텝마다 훅훅 바꾸지 말고 살짝씩 바꾸자.
- Stochastic - 확률 => 시작 지점이 랜덤이다
rmsprop
- 이전 히스토리를 봐가면서 내려가자
adam
- rmsprop과 momentum을 둘 다 섞어쓰자

2-2) InitialLearnRate
경사하강법에서 사용되는 내용인데 한번 내려갈 때 스텝 사이즈를 조정하는 옵션이다.
2-3) MiniBatchSize, Epoch
Epoch란, 전체 데이터셋을 한 사이클 돌면서 학습을 진행했다는 뜻이다.
Epoch가 100이라는 뜻은 전체 데이터셋을 100번 돌면서 학습했다는 뜻.
MiniBatch란 전체 데이터 셋을 n등분으로 쪼갠 부분 데이터 셋이다.
이 부분 데이터셋 하나 하나가 전체 데이터 셋을 대표한다고 가정하고 각각 가중치를 학습한다.
예를 들어서 전체 데이터의 개수가 1000개이고, MiniBatchSize가 100이라면,
Epoch 한 사이클 당 10번의 학습이 이루어지게 된다.
+) 왜 MiniBatch를 사용하는가?
- 전체 데이터를 모두 고려해서 한번 학습하는건 성능은 확실할지 몰라도 시간이 오래걸린다
- 부분 데이터를 가지고 학습하는건 시간이 빠르다
+) Epoch 값을 크게 하여 수백번 수천번 학습시킬수록 더 좋은 네트워크인가? - (X)
- 오히려 과적합 문제로 Loss율이 더 증가할 수 있다
- 적절한 수준에서 끊어주는 것이 좋다
+) MiniBatch 사이즈는 학습 성능에 큰 영향을 끼친다.
너무 크면 -> 데이터셋의 제로패딩 크기가 너무 커진다(이후 RNN&LSTM 내용과 관련) / 메모리 크기 초과 등..
너무 작으면 -> 학습의 Iteration마다 성능이 들쑥날쑥해지면서 학습성능이 저하된다
--> Data Preprocessing으로도 제로패딩 줄이기 등 성능향상이 가능하므로 MiniBatch 사이즈 조절은 신중하는 것이 좋다.
2-4) Validation 관련
ValidationData: validationData 지정
ValidationFrequency: Epoch n번 주기로 validation 셋으로 모델을 평가한다
이걸 다 섞어서 코드로 표현하면 다음과 같다
options = trainingOptions("sgdm", "MaxEpochs", 50, "MiniBatchSize", 128,...
"InitialLearnRate", 0.0001, "ValidationData", valData,...
"ValidationFrequency", 10, "Plots", "training-progress");

이제 옆에 써져있는 말들이 이해가 된다.
Epoch: 50회 -> 전체 데이터셋을 50 사이클 돌았다
Epoch당 반복 횟수 -> MiniBatch(부분 데이터셋)이 23개 있어서 한 Epoch 사이클을 돌 때 23번 학습한다
검증 빈도 -> Epoch 10 사이클마다 validationData로 네트워크 성능을 평가한다
- 과적합(Overfit) 문제와 관련.
-----
# 네트워크 성능 향상 방안
핵심) MaxEpoch와 InitialLearningRate는 짝꿍!
1. MaxEpoch가 너무 크면 과적합(Overfit) 문제가 발생할 수 있다.
- Loss율을 보고, 더이상 Loss가 줄어들지 않고 계속 평탄하게 유지되면 적절 선에서 끊어주는 것이 좋다.
- 위 상황을 plateau(플래토, 평원, 안정을 유지하다) 상태라고 한다.
- MaxEpoch가 너무 크면, Loss율이 오히려 올라가는 경향을 보인다.
(모델이 train 데이터에 너무 과적합되어 예측 score값이 오히려 떨어짐)
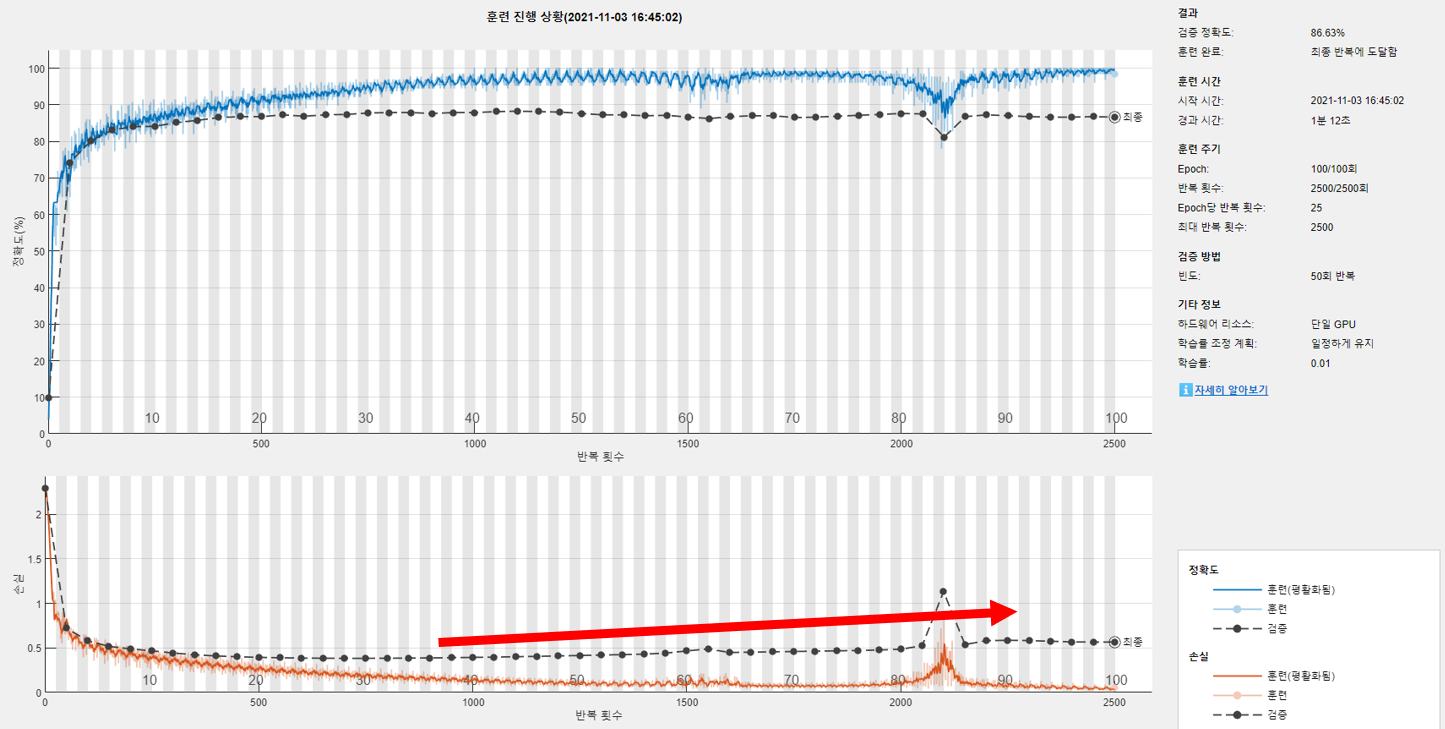
2. InitialLearningRate는 너무 크면 발산할 수 있다.
- 다만, "시간" 또한 학습에 중요한 요소이므로, 0.01 부터 시작해 10의 배수 단위로 테스트해보는 것이 좋다.
- MaxEpoch를 줄이고, InitialLearningRate를 늘이는 식으로 학습 시간을 단축시켜볼 수 있다.
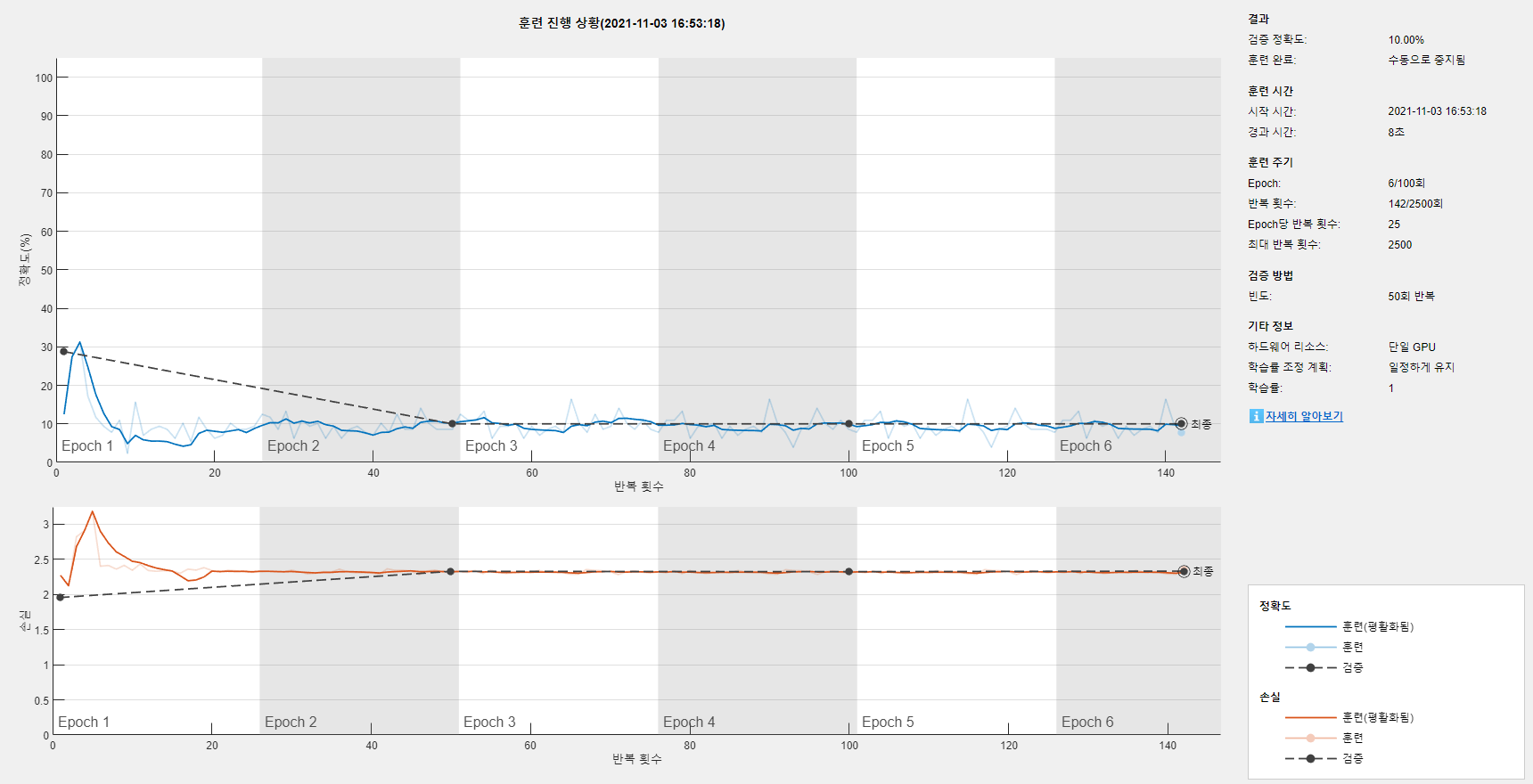
3. Validation은 필수적으로 진행하는 것이 좋다.
- 과적합 상태를 판단하는데 필수적.
<Flow Chart>
1. 학습 모델이 수렴 하는지?
- 수렴하지 않는다면 InitialLearningRate를 줄여보자
2. 학습이 끝나고 나서도 Loss율이 더 줄어들 기미가 있는지?
- 더 줄어들 기미가 있다면 MaxEpoch를 더 늘여보자.
3. plateau 상태에서 Loss율이 증가할 기미가 보이면 MaxEpoch를 줄여볼 필요가 있다.
<기타 옵션을 사용하는 방법>
1. "LearnRateSchedule" 옵션을 이용해 InitialLearningRate를 유동적으로 조절할 수 있다.
2. "L2Regularization" 옵션으로 데이터 정규화하여 과적합을 막는다.
3. "GradientThreshold" 옵션으로 기울기의 임계값을 지정할 수 있다. (이게 어디에 좋은지는 잘 모르겠음)
opts = trainingOptions("sgdm", "MaxEpochs", 30, "InitialLearnRate", 0.1,...
"Plots", "training-progress", "ValidationData", {val_x, val_y},...
"LearnRateSchedule","piecewise", "LearnRateDropPeriod", 5, "L2Regularization", 0.001, "GradientThreshold", 1);
이외에도 네트워크 레이어를 더 deep하게 구성하는 방법을 사용할 수 있다.
'학교공부 > 인공지능' 카테고리의 다른 글
| 매트랩으로 배우는 인공지능 - 9 | 스펙트로그램(Spectrogram) (0) | 2021.11.17 |
|---|---|
| 매트랩으로 배우는 인공지능 - 8 | Regression (0) | 2021.11.17 |
| 매트랩으로 배우는 인공지능 - 6 | CNN 레이어 상세 (0) | 2021.10.06 |
| 매트랩으로 배우는 인공지능 - 5 | Training from scratch (0) | 2021.09.30 |
| 매트랩으로 배우는 인공지능 - 4 | Convolution, ReLU, Pooling (0) | 2021.09.30 |