
티스토리 뷰
1. COUNT(필드)
- 개수를 센다
SELECT COUNT(*) AS "총 직원수" FROM tStaff;
SELECT COUNT(*) FROM tStaff WHERE salary >= 400;
SELECT COUNT(depart) FROM tStaff;
SELECT COUNT(DISTINCT depart) FROM tStaff;
SELECT COUNT(*) FROM tStaff WHERE score IS NULL;
SELECT name FROM tStaff WHERE score IS NULL;
SELECT COUNT(*) FROM tStaff WHERE score >= 80;- COUNT(DISTINCT 필드) 를 통해 중복을 제거한 필드의 총 개수를 셀 수 있다
- 목록은 상관없고 개수만 세고싶을때 사용
2. 합계와 평균
SUM, AVG , MIN, MAX
STDDEV : 표준편차
VARIANCE : 분산
SELECT MIN(area), MAX(area) FROM tCity;
SELECT SUM(score) AS "합계", AVG(score) AS "평균" FROM tStaff WHERE depart = '인사과';
SELECT MIN(salary) AS "최소", MAX(salary) AS "최대" FROM tStaff WHERE depart = '영업부';
SELECT MIN(name) FROM tStaff;SUM, AVG 함수는 문자열에 사용할 수 없다
다만 MIN, MAX 함수는 사전순으로 비교할 수 있어 문자열에도 사용할 수 있다
3. 0과 NULL은 다르다
- 모든 집계함수는 NULL을 무시하고 집계한다
>> 예외 : COUNT(*) << ... 다만 인수로 특정 필드를 지정한 COUNT(필드)의 경우는 NULL을 무시하고 집계한다
COUNT(*)은 조건을 만족하는 레코드가 없으면 0을 리턴한다
나머지 집계함수는 조건을 만족하는 레코드가 없으면 NULL을 리턴한다
SELECT COUNT(*) FROM tStaff WHERE depart = '중국집'; -- 0
SELECT MAX(salary) FROM tStaff WHERE depart = '중국집'; -- (NULL)
4. GROUP BY, 그룹핑
SELECT depart, AVG(salary) FROM tStaff GROUP BY depart;
SELECT depart, COUNT(*), MAX(joindate), AVG(score) FROM tStaff GROUP BY depart;
SELECT region, SUM(popu) FROM tCity GROUP BY region ORDER BY SUM(popu) DESC;
SELECT depart, gender, COUNT(*) FROM tStaff GROUP BY depart, gender;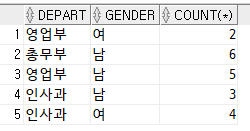
기준 필드를 두개 이상 쓸 수도 있다
-> 첫번째 기준으로 그룹을 나누고, 그 안에서 두번째 기준으로 그룹을 나누고 하는 방식.
- GROUP BY절이 있으면 필드 목록에는 기준 필드나 집계함수만 올 수 있다
결론
SELECT 기준 필드, 집계함수1(), 집계함수2(), ..., FROM 테이블 GROUP BY 기준필드;
5. HAVING
- HAVING은 GROUP BY 다음에 오며, 결과 중 출력할 그룹의 조건을 지정한다
-> HAVING은 GROUP BY문의 조건절
SELECT depart, AVG(salary) FROM tStaff GROUP BY depart HAVING AVG(salary) >= 340
ORDER BY AVG(salary) DESC;GROUP BY -> HAVING -> ORDER BY 순서로 와야함
Q) WHILE 절과 무슨 차이가 있나?
- 조건을 적용하는 단계가 다르다.
SELECT depart, AVG(salary) FROM tStaff WHERE salary >= 340 GROUP BY depart;
SELECT depart, AVG(salary) FROM tStaff WHERE salary > 300
GROUP BY depart HAVING AVG(salary) >= 360 ORDER BY AVG(salary);
SELECT region AS "지역명", MAX(area) AS "면적(km^2)" FROM tCity WHERE popu >= 50
GROUP BY region ORDER BY MAX(area) DESC;
SELECT region AS "지역명", AVG(area) AS "평균 면적" FROM tCity
GROUP BY region HAVING AVG(area) >= 500 ORDER BY AVG(area) DESC;1. WHILE 절이 레코드를 대상으로 필터링
2. GROUP BY로 그룹핑
3. HAVING 절으로 그룹을 대상으로 필터링
4. ORDER BY 절으로 마지막 정렬
결론
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY
'SQL' 카테고리의 다른 글
| SQL 뽀개기 - 6 | 제약조건 (0) | 2021.07.24 |
|---|---|
| SQL 뽀개기 - 5 | 삽입, 삭제, 갱신 (0) | 2021.07.23 |
| SQL 뽀개기 - 3 | SELECT (0) | 2021.07.22 |
| SQL 뽀개기 - 2 | SQL의 종류 (0) | 2021.07.22 |
| SQL 뽀개기 - 1 (0) | 2021.07.21 |